Does distributed data products work for low latency searches or lazy reporting ?
Lately, Data Mesh has gained prominence when the pain of ingesting all the data in one datalake and the data engineering teams controlling everything gave into distributed teams managing their data domains.
Data Mesh is viewed as a solution to many data-dependent use cases like., reporting, analytics, queries, etc. Datalake architecture does solve all these use cases. In some cases, it performs better. However, Data Mesh prompts unblocked parallel development.
Having said this, I struggled to understand how does the distributed data domain concept solve low latency adhoc queries, or lazy reporting use cases. Specially when the end user is on mobile, webapp or want quick answer. This is something where solutions like elastic search, read replica partitioned and indexed DBs etc. works pretty well.
Lets understand in brief what Data Mesh is and use cases or advantages where it helps.
Data Mesh – Brief Introduction
Data Mesh, in simpler terms, decentralizes data lakes or data warehouses. It is similar to how microservices break down a monolithic application.
It hands over the responsibility to ingest, curate, cleanse , store and allow consumption of “data as a product” to the team who understand that data best i.e., the data domain teams. Obviously each team has to follow the data governance principle and should leverage the core data engineering solution developed by the data platform team as much as possible.
The data domain team is responsible to share the data to the data consumer teams/applications through standard well defined interfaces. All this happens under the allegiance of central data engineering or platform team which manages data governance and promotes reusable data pipeline solutions or architecture. The data products should be registered with catalogs for consumers and everyone to discover the product and the products metadata (schema etc.)
Although you can have a centralized data pipeline or template infrastructure but it should be more of a reference implementation. There has to be given enough flexibility to the data products and the consumers team.
The key characteristics of a good Data Mesh implementation is :
- Very clear data boundaries, well defined data product without lot of cross cutting. Similar to domains concept in DDD.
- Well maintained data catalog with schema, owners, access patterns for the data products. The key element definitions and names should remain the same across the products so its easy to cross reference or join them.
- Each data product should have standard way to consume the data. There should not be lot of customized patterns to consume the data.
- Each one should follow standard governance practice to that we can trust the data.
Cloud services make it easy to implement the Data Mesh architecture. We can’t discount this point. Imagine how difficult it will for each team to provision their own hardware and toolset.
So far so good. As the data is distributed, it leads to complexity for low latency adhoc queries usecases.
Why supporting quick response searches is a problem
On demand reporting, or any usecase which requires quick query with data related to different domains need to prepare the data at common place to cross reference and join them. Also the data should be stored in a database which is optimal for the consumer like., for text search ElasticSearch, geospatial supported DB or graph supporting DBs.Data Mesh prescribes that the data should be distributed and with the owners only and should be consumed on need basis with no duplicate storage. Data Mesh is a network of data domains. If you need to optimize for low-latency, this distributed data will not work. I think these are two opposite thoughts. For example., you have a data product representing the Payments Transaction and another domain is related to customer master data. Any report will have to stitch these two data products. These are not just OLTP which can be easily managed. Users would like to check historic data like.., a payment done 3 months back to Party A end understand the charges incurred. These are quick search usecases and not monthly MI reports or a daily live dashboard which works on a limited data set.
What are the options
One thought process, is to create complex caching layers or data virtualization solutions or building cubes. It’s like solving a problem that should never have existed in the first place.
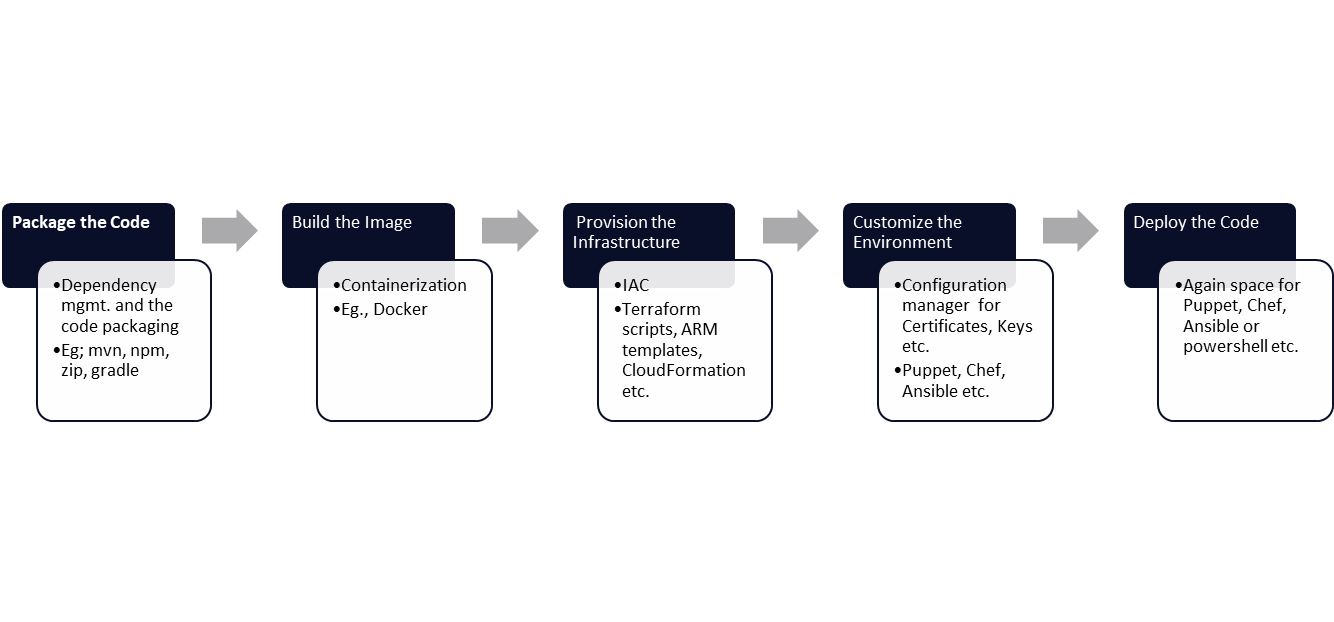
The practical way to solve this is to go with likes., of CQRS on data mesh (the way microservices solve such problem). Query from read replica databases, and horses for courses data storage systems like elastic search, Document DB , Indexed and partitioned RDBMS or even in some scenarios caches.
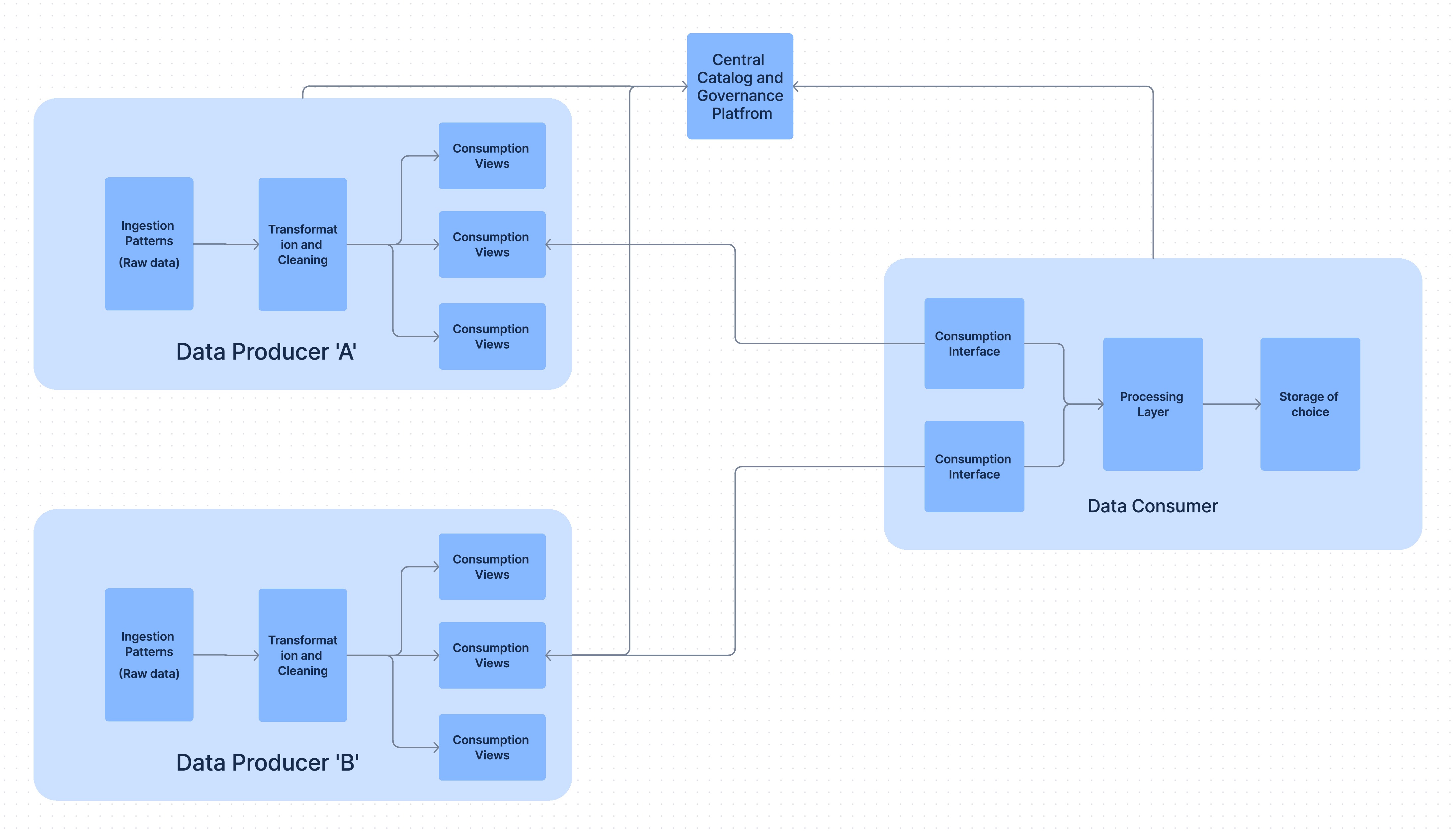
This works even in the Data Mesh paradigm. Data Mesh actually allows to create data domain based on the consumption perspective as well. This means an application responding to quick queries can prepare its own consumer data domain.
Data Mesh doesn’t restrict from including other domain’s data (payments transaction and customer data), provided the data is transformed (joined in this case), and persist it (DataStore relevant to final use case). The consumer team can take ownership of this new transformed data product. This is what is known as the consumer aligned data domain. Another advantage is you can distribute the read workloads and may lead to cost saving as well.
Can this be a data product, it depends on the consumer team. If they think that this is relevant for others then it should be registered with the catalog teams and proper lineage should be made available.
Long story short, it is OK to prepare the data beforehand and give consumers enough room to operate. This is win win situation as everyone can participate in evolving the data platform and without compromising on critical business non functional requirements.